How to master the SGA and PGA in Oracle databases

As we are talking about Oracle databases here, you are probably aware of the system global area (SGA) and program global area (PGA) in Oracle, which play a crucial role in database memory management. Let us explore memory allocation in detail and how to configure these for peak efficiency.
The SGA and PGA in Oracle a...
Maximizing ROI in server monitoring: A strategic approach for businesses
According to the 2024 Statista report on global crucial data center IT outages from 2020-2023 , power disruptions have become the leading cause of outages, rising from 37% in 2020 to 52% in 2023. This shift highlights an increasing vulnerability in infrastructure reliability, making proactive server monitoring more critical than eve...
Using eBPF for modern IT observability: challenges and opportunities

Today, eBPF is a powerful, widely accepted technology that operates at the kernel level of the operating system. It enables real-time, low-overhead monitoring of system calls, network traffic, and resource usage across applications and containerized deployments. Celebrated system performance expert and author Brendan Gregg once quipped that &...
Diagnosing and resolving high latency in AWS EC2 instances
AWS EC2 instances drive cloud applications with scalable compute power, but high latency can disrupt even robust setups. A gaming server lagging mid-match or an e-commerce site stalling at checkout shows how delays can affect users and hurt the bottom line. Latency often stems from overloaded CPU or memory, network bottlenecks, slow storage, ...
How SNMP traps help prevent network failures: A use case analysis

Optimizing Kubernetes node resources: How to avoid exhaustion and improve performance

When a node is low on resources—as in CPU, memory, or storage—a workload may suffer from failures, degraded performance, and eviction.
If you want your cluster to run smoothly, it's time to learn how to identify the root causes of your node resource exhaustion and take proactive steps to mitigate them before something g...
From surface-level to strategic: Benefits of network traffic analysis

How to get started with error budgets to meet SLOs for improved service reliability

SLOs also mark the maximum error amount or period a system is allowed to experience within a timeframe to be judged as acceptable. Akin to a financial budget, an error budget expresses the things gone wrong (errors) as a percentage of the total time or requests that transpire in a timeframe: for example, 1% of monthly requ...
From failure to fix: Diagnose Kubernetes Node and Pod problems with Site24x7

Picture a busy Monday morning. You are working on leftover projects from the previous week, and assuming everything is fine with your applications as you had not received support tickets during the weekend. All of a sudden, during the middle of the day, you get a flood of reports from users who complain about slow response in your application...
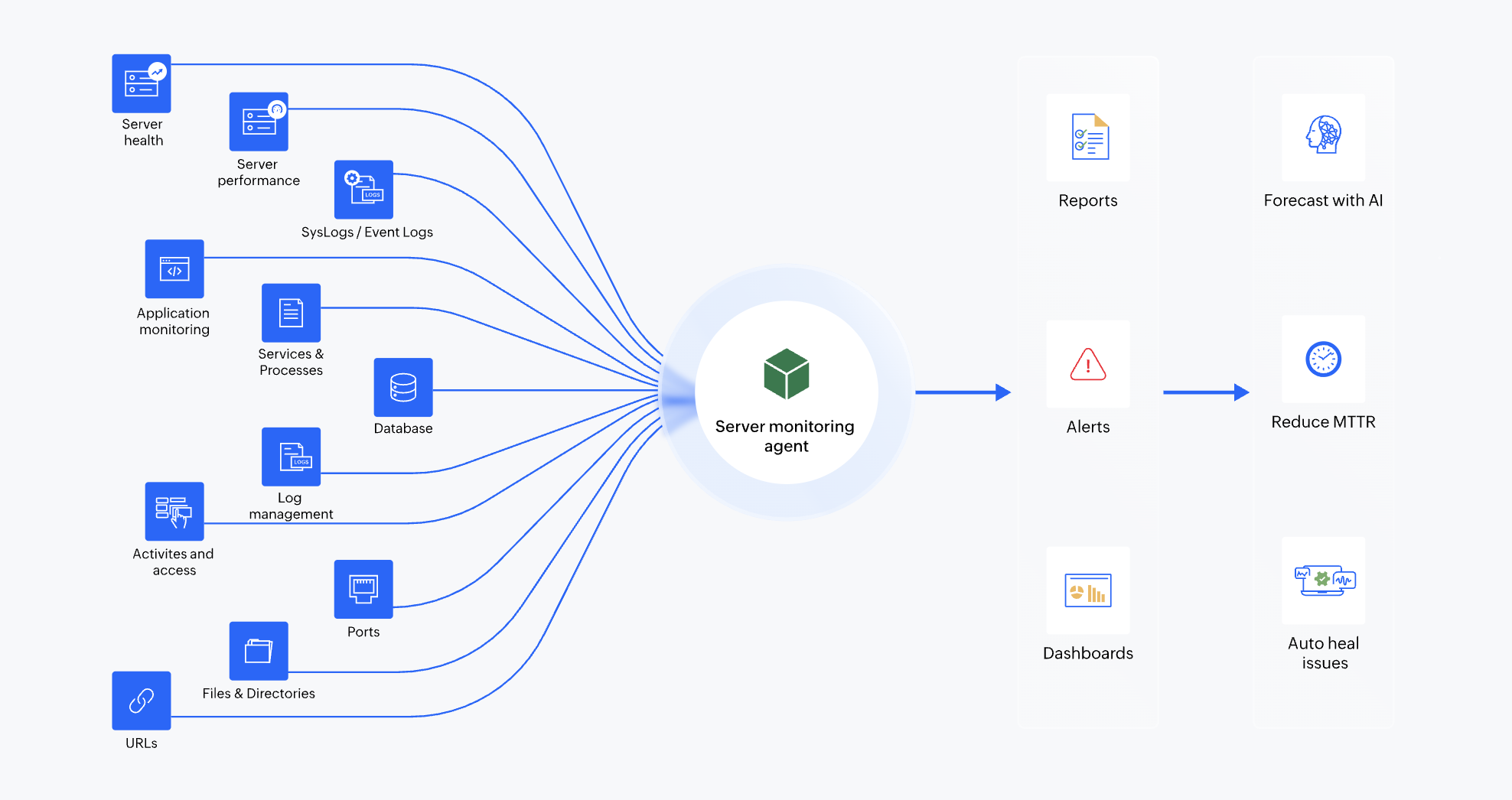
Server monitoring checklist

Do you ever look at the list of metrics you monitor and feel overwhelmed? That is a nice problem to have instead of needing to tweak your server performance KPIs because your server monitoring tool does not monitor them. With Site24x7's server monitoring suite, it is easy to be spoiled for choice when it comes to which metric to mon...